
- 19 Dec, 2019
- read
One of the best practices while developing software, now recognized everywhere, is to use any kind of source control management tool to keep your code, its time-line, and versioning.
Nevertheless the organization of the SCM repos is still open to interpretation by whoever is using it. Most of the time multiple developers have their own ideas on how to leverage the different features a SCM tool brings to the table (branches, tags, naming, etc).
In this post I will cover my mental models of two different strategies that try to standardize branching.
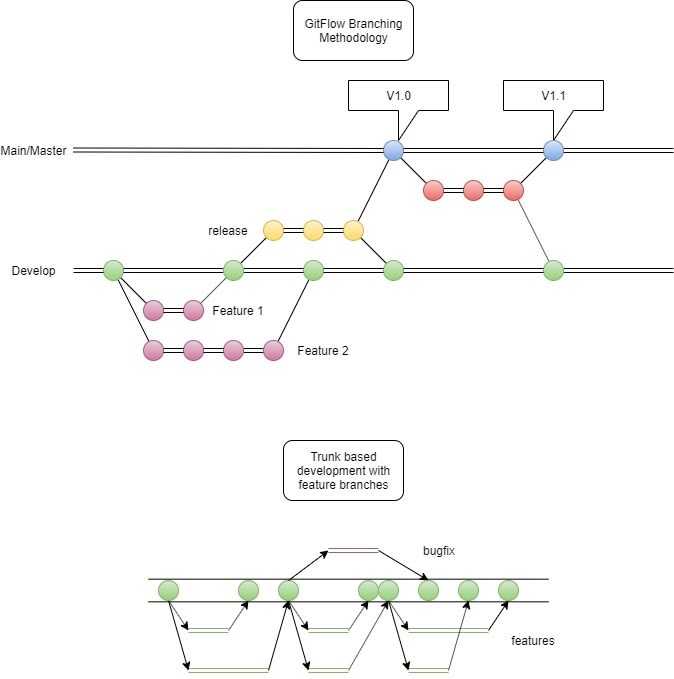
GitFlow
Arguably the most known branching strategy to manage branching in git-the stupid content tracker(yes, that’s the full, real, name of git). In this strategy, there will be a set of 2 persistent branches, each with its specific purpose:
-
main/master: This branch will be used to track only the released versions of the software we are developing. NO ONE SHOULD EVER TOUCH THIS BRANCH DIRECTLY.
-
develop: As described by its name, this branch is where main development and changes will happen, is where the the story of all the development will reside. Again NO ONE SHOULD TOUCH THIS BRANCH DIRECTLY!
I can hear you already asking “Then, where the hell do I work and commit my code!?”. Well you will work on temporary/transient branches, and depending on what type of work you are doing you’ll select the correct branch. The usual temporal branches are:
-
feature/my-feature: If you’re gonna work on anything that will add new functionality it belongs into a feature branch. Each feature branch will hold commits that belong only to the functionality it’s adding. These branches are created from develop and will merge back into develop (ONLY WHEN THE FEATURE IS AS READY AS IT CAN BE!).
-
release/0.0.1-SNAPSHOT: HURRAY!!!, your software source code is full of new feature already merged into the branch develop! This branch is created from develop when a new-feature set is complete enough to release it to the public/client as a new version of your software. In this branch you’ll polish your app & code, and hunt for as many bugs as you can. Once the team is happy with the state of the software in this branch it is ready to finally be merged with the master branch(Once merged it’ll be finally considered as a newly release of your software, yay!). now when you merge it to master remember to merge it back to develop, so everything you corrected/fixed in this branch will be stored in the story of the software and will be taken in account when new features are added.
-
hotfix/0.0.2-SNAPSHOPT: Soooo well, yeah, no one is perfect. This branch are there for when an oopsie makes all the way to master. This branch is born from master and its summoned to existence when a bug appears in production. Whatever work is done in this branch is done towards the resolution of the bugs that were found. When the bug is fixed it is merged back to master(effectively creating a new version) and back into develop so the bugs are squashed in both permanent branches.
As described GitFlow is shown as methodical and tries to ensure coordination of the developers by leveraging the use of groups of branches. Its organization and sequential steps give control over what is getting to master/production.
But for me it has several disadvantages:
- It’s complex to understand a first.
- Encourages the existence of what is know as “dev complete” (goes against agile).
- Makes cumbersome the attempt to have CI. And when CI is done it becomes over-complicated.
- Frustrates the attempt to implement a continuous deployment scheme.
- Precludes the assurance of parity between code environments.
- Can still lead to Integration hell.
To be fully honest it seems like a good control strategy to implement whenever a team is using a waterfall methodology and plans cautiously its release schedule.
Trunk based development
Less is more.
Trunk based development is called like that because it only has one permanent branch called either master or trunk. This single branch represents the complete history of the project. Even thought some purists insist that this should be only one branch, and no more branches should be created; what trunk based development expects is that no other branch aside from master/trunk should be long living. Ensuring this we can avoid code disparity over time and engage CI/CD practices in a more consistent way. So basically you can create any kind of branch you want/need to organize or isolate your work as long as it is short lived and gets merged into master ASAP.
So the usual way of working(in the teams I’ve been) is using 3 kinds of branches:
-
master/trunk: Long live the trunk. This is the main branch and the only one that should live more than a few days in the repository. It actually keeps track of everything that ever happened to the code and is the source of truth for the productive code.
-
feature: Short lived branches where you isolate your work when creating new functionalities. These branches should be cut down and merged back into master as soon as the new feature is ready.
-
bugfix: Again no one is perfect and when a bug arise in the master branch. This short lived branch helps to isolate the work done to solve the bug that was found. Again, THIS SHOULD BE MERGED ASAP TO TRUNK!
As you can read everything should go back to trunk/master ASAP. This branching methodology enables your team to easily implement CI/CD practices, but to achieve the most from this branching strategy you need a mature self organized team that also uses CI/CD practices. (Everyone should be doing CI/CD TBH).
And I can already see you wondering “Well then how the fork we know what should go into production, is there any vesioning strategy? it could really work using only one branch?”. Usually a tag is used for versioning on the master branch and every single commit to that branch can be considered a new version.
So now you have the whole story on one branch, and the versioning as well. E voila, everything you need is on your beloved trunk.
Using TBD we are avoiding integration hell and enabling CI/CD practices.
The disadvantages are:
- The need for a mature self organized and responsible team.
- The need for CI/CD practices to enjoy the best of this strategy.
Diagrams
For the sake of using images, here I’ll show you a (lazy done) graphical representation of both strategies:
WoW, you got to the end. Thank you for reading, this is the first time I decided to publish anything. I hope you liked this rant about branching and that it may be useful in any way.